不要再用K-means! 超實用分群法DBSCAN詳解
近期跟別人聊到Clustering(分群法)時,發現大部分的公司、專案,大家都還是在使用非常傳統的K-means分群法,但是K-means其實使用起來難度並不低,大多數人可能會因為不知道要設定最終幾個cluster,或是因為K-means效果太差而乾脆不做分群。
所以我打算在這篇文章中介紹一個我個人很常用的分群法 DBSCAN,並且說明要如何調整DBSCAN的參數,後續文章會介紹另外一個更強大的分群HDBSCAM。
在這篇文章我會講零、為甚麼要做分群
一、DBSCAN概念
二、sklearn DBSCAN使用方法與例子
三、如何設定DBSCAN的參數
零、為甚麼要做分群
分群法(Clustering)是每一堂ML課程都會教,但是卻非常少人在使用的方法,在ML的分支裡面我們往往會用下面這張圖來介紹,告訴你分群是屬於非監督式學習的一種(Unsupervised)。

但是往往大家真正在使用的時候就會疑惑
分群(clustering)跟分類(classification)到底差在哪???
如果我們看重的點是「有沒有Label」的話,那的確對我們來說,除了「有沒有Label」這個差異以外,分群跟分類做的事情幾乎一模一樣。
這就導致了,當今天有Label的時候,不會有人考慮分群,而沒有Label的時候,即便做了分群大家也不知道具體能夠用來幹嘛。
這個問題來源於
對非監督式學習的目的沒有正確的理解。
我在這篇文章中沒有足夠篇幅解答這個問題,但是這邊舉一個簡單的例子,在客戶分群(Customer Segmentation)裡面,我們常使用RFM analysis,但是我們不會在做完RFM後就直接把結果當成我們最重要的輸出,而是做完RFM後再針對每個segment去深入做分析或建模。
具體不清楚RFM analysis在幹嘛的朋友可以參考這篇
Takeaway 1: 分群通常只是流程中的一環,而非全部這邊從RFM我們看到一個分群的使用方法,先對所有資料或用戶進行分群,然後再針對每一群去做進一步的分析、建模,
Ex: 先做Clustering再做Supervised Learning
實際上這種方法在推薦系統中非常常用
一、DBSCAN概念
DBSCAN全名Density-based spatial clustering of applications with noise,詳細介紹其原理的文章已經很多了,這裡我只提兩個重點。
- DBSCAN是所謂Density-Based的方法,也就是他最重視的是data的密度
- DBSCAN能夠自動處理noise
而除了這兩點以外,DBSCAN最令人稱羨的一個特性是
DBSCAN會依據data性質自行決定最終Cluster的數量
所以我們在使用K-means或是其他較傳統的分群法時,我們遇到最大的困難:要事先設定最終的Cluster數量這點,在DBSCAN裡面並不存在。
而DBSCAN的核心概念就是下面這張圖。
DBSCAN會自行從任意一個點出發,以上圖而言假設從A出發,然後搜尋A周圍eps範圍以內的「資料數量」,當前的eps範圍裡有超過min_samples個資料時,我們就認為A是一個Core,然後開始去對A的eps範圍內的其他資料做一樣的事情,直到現在某一個點的eps範圍內不具備min_samples數量的點了我們就停止。
而如果今天出發的點是N,則在最一開始周圍就找不到足夠數量的點,所以N就會被判斷為Noise。
可以看下圖gif來參考完整運作流程。

這個精美的GIF是來自於下面這篇Medium,如果有開通會員的很推薦去看一下這篇。
Takeaway 2: DBSCAN 3大好處1. 自動依據data特性決定cluster數量
2. 自動找出noise並排除掉
3. Cluster的形狀可以千奇百怪,只要密度夠高這3個也是傳統clustering最要花時間處理的部分。
不過我們現在要決定的就是eps要多大,min_samples要設多少,這會在第三部分講解
這邊大家也可以從身邊的例子思考,在讀書的時候相信大家都有參與過班級上的「小團體」,今天要把班級裡面的人分群,我們並不是先決定最終有幾群,而是從任意一個同學出發,找到跟他比較要好的幾個同學,藉此來決定他們的小群體是哪些成員,DBSCAN就是使用這種直覺的方法來運作。
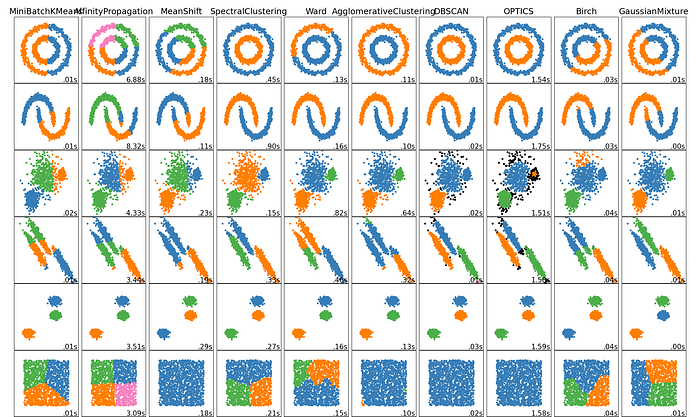
這邊也可以參考sklearn自己做的各個Clustering效果比較,其中應該可以輕易看出DBSCAN效果是裡面數一數二好的(另一個表現很好的就是OPTICS,本質跟DBSCAN很像)
二、sklearn DBSCAN使用方法與例子
DBSCAN的使用方法非常簡單,這裡直接看sklearn裡面的例子
from sklearn.cluster import DBSCAN
import numpy as np
X = np.array([[1, 2], [2, 2], [2, 3],
[8, 7], [8, 8], [25, 80]])
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
clustering.labels_
clustering就跟一般的sklearn的clustering方法一樣,我們把hyperparameters設好之後,我們只要使用.fit(),就可以自動幫我們做好clustering。
而DBSCAN在使用上最最最最最重要的hyperparameters也只有兩個,第一個是eps,也就是我們每個點「要搜尋的周圍範圍要多大」,還有min_samples,也就是我們認為一個範圍內「有多少個點以上」才算密度夠高。
偶爾我會設另一個hyperparameter,也就是下圖的第三個metric,因為我們預設計算資料間的距離都是算L2-distance,或是稱為Euclidean Distance,但是在某些特定的資料上,我們可能會希望計算cosine similarity(像是做在NLP的embedding上時),甚至其他更複雜的Distance,這種時候就要改metric。

而DBSCAN最重要的output就是.label_的資訊
clustering.labels_其中數值會從0, 1, 2 …到N,代表我們總共有N+1個clusters,而如果其中出現-1的話,-1代表noise。
Takeaway 3: 使用的重點
hyperparameters: eps, min_samples最重要,metric偶爾調,其他盡量不要動
fit完後叫.labels_出來看每一個data point的cluster編號,其中-1代表noise。三、如何設定DBSCAN超參數
這邊可能就是大家最在意的重點,DBSCAN看似很好用,但是我們那兩個hyperparameters到底要怎麼設定,我這邊提供幾種方法。
一、依照noise的數量調整
一般我們一份data裡面先做完EDA,會對這份資料大概有多少比例的noise有一些概念,所以當我們發現DBSCAN抓出來的noise太多或太少時,我們可以再去調整我們的超參數
noise太多 ==> 加大eps,縮小min_sample
太少反過來
注意不要讓eps跟min_sample變成太極端的值二、依據Domain Knowledge
在很多資料中,我們其實會對甚麼範圍以內的資料應該算在同一個cluster有概念。像是年齡、年收入、身高體重…
依據我們對這個問題的理解,我們可以客製化我們認為的eps應該為多少,找到一個好的起始點再去細節調整數值。
這邊要注意的是如果feature很多,我們必須要對每個feature做「良好的Scaling」,避免單一feature主導了整個距離的資訊。
三、依據downstream task performance
如果我們的Clustering後還有接Supervised Learning,我們可以直接依照Supervised Learning的Performance來調整clustering的參數。
四、依據k_distance
k_distance的意思就是,第k近的點跟我的距離,這個功能可以很快速地用knn做出,而我們可以藉由不同的k,來看我們的資料在不同範圍內有多少個點,或是這些點的性質跟我們中心點是否一致。
五、持續做Data Analysis
這是最困難但也最核心的方法,藉由不斷的對Data做分析,我們對我們的資料有更深入的理解,就會知道哪些點應該被分在同一群,藉此再去調整我們的超參數。
六、依據Cluster數量大致決定
很多問題我們其實會有一個預設的最終Cluster數量,像是客戶分群我們可能預設就是分成10群上下,超過10群我們可能也沒有這麼細緻的策略,這種時候我們其實有點把DBSCAN的優點「不用知道總共幾個cluster」給放棄了,但是DBSCAN能夠處理noise,並且cluster形狀不會被限制這兩大優點,還是讓他比K-means好用非常多,所以也可以依據Cluster數量調整。
DBSCAN的介紹大概就到這邊,如果有疑問可以再回復跟我討論~
下次會再介紹更進階的HDBSCAN給大家(已完成 請參考下面連結)
如果喜歡這篇文章可以幫我多拍手幾次XD,或是對於哪個類型文章有興趣都可以在留言區跟我講~ 後續會以中難度的ML/DS/AI知識為主,以及AI/HCI研究相關知識