分群法(Clustering)是很多新手Data Scientist或是ML scientist不知道如何使用的工具,導致很多人在工作流程中從來沒有使用過分群。
最大的問題就是,一般課堂、書籍中教的Clustering方法(像是K-means),都不容易上手,包含超參數不好調,很難快速達到好的效果。(實際上 K-means仍然是很實用的方法,只是需要更多經驗才能用的好)
在上一篇我介紹了一個我自己非常非常愛用的Clustering —DBSCAN,並且快速了介紹其原理跟使用技巧,相信大家可以很快速上手DBSCAN,使用在自己project中或是在面試中提起,還沒有看過的朋友推薦先去看DBSCAN的介紹。
但是在DBSCAN的使用上其實兩個超參數eps、min_samples還是不容易調,並且DBSCAN也有其最大的限制。
DBSCAN預設了所有cluster的密度是類似的,所以我們可以藉由eps跟min_samples給定特定的密度來進行分群,但是這個假設通常不成立。
而HDBSCAN就是為了解決這個問題而存在的
在這篇文章我會講一、HDBSCAN簡介
二、如何使用HDBSCAN
三、Clustering效果比較
針對HDBSCAN深入的原理說明將會在之後的文章補充說明,但是其實大家並不需要詳細了解原理,只要了解我的基礎介紹就好了。
一、HDBSCAN簡介
HDBSCAN的是Hierarchical DBSCAN的縮寫,HDBSCAN的優勢在於
- 只剩一個超參數min_cluster_size要調
- 不會受限於DBSCAN對於cluster密度的限制,接下來我快速說明這點
DBSCAN假設了所有cluster有類似的密度,而這是一個嚴重的問題
我們來看一個具體的例子。如果我用sklearn的make_blob做出來下圖這筆data。

現在請大家先在腦中試想,如果是你你會怎麼把這筆Data進行分群?
我想大部分人應該會做類似下圖的分群,總共把data分成兩群,以及散在周圍有一些noise。

這個結果應該滿單純的,但是這裡的範例data其實就有「兩個cluster密度不一」的問題,而這會讓我們在使用DBSCAN時不太好tune。

這邊可以看到,即便我手動挑了一個不錯的起始超參數,我改動一點數值,滿容易突然就爛掉了。
這就是當cluster密度不同時,DBSCAN會遇到的困境,那下面直接來看HDBSCAN的效果。
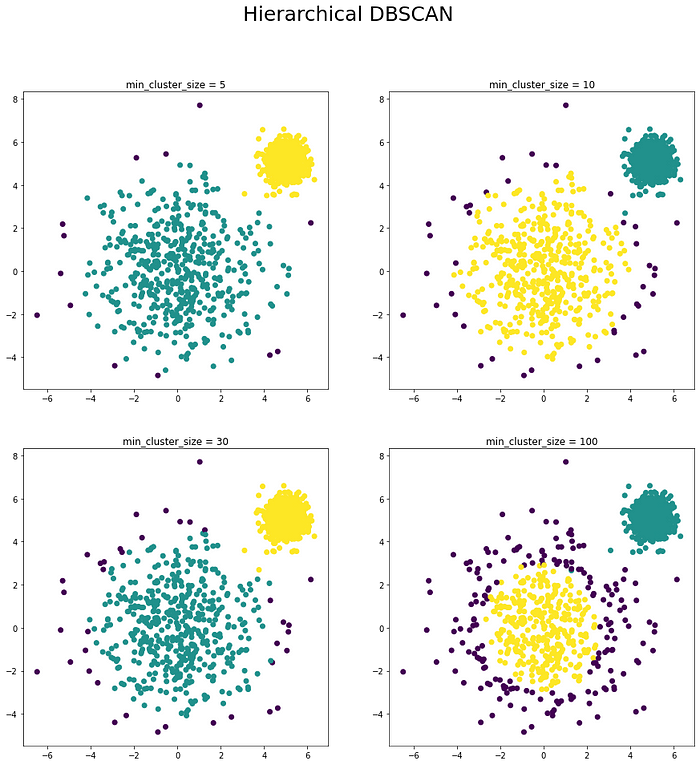
這邊可以看到HDBSCAN在超參數的數值差異很大的時候,仍然具有一定的robustness(上面4個結果都是可以接受的結果)。
並且因為HDBSCAN只剩下一個超參數要調,所以使用起來難度也非常非常低。
HDBSCAN 優點1. 比DBSCAN更robust
2. 只有一個超參數要調
3. 不會受限於cluster的形狀與密度
這邊可能會有人好奇那K-Means做起來會怎麼樣,下圖是Kmeans在已知最終只有2個cluster時做出的效果,可以發現還是相當糟糕。

二、如何使用HDBSCAN
這裡要介紹一個package就稱為hdbscan,這是一個scikit-learn-contrib的package,也就是說他用法跟sklearn幾乎一樣並且可以輕易接上大部分sklearn的其他method。
hdbscan的下載相當容易
pip install hdbscan
或
conda install -c conda-forge hdbscan在windows上使用pip裝hdbscan可能會遇到一些環境問題(Visual Studio版本不對),我建議可以用conda,應該相對問題比較小。
而使用上跟sklearn大部分的clustering一模一樣,可以參考下面的code,基本上最重要的就是
.fit() : 用來train clustering
.labels_ : train完後取出每個data屬於的cluster number而HDBSCAN最重要要調的參數就是min_cluster_size,這邊就很直觀的設你認為最小的cluster要包含多少data point就好,或是也可以先隨意給個數值,效果通常都不錯。
其他hyperparametes在官網的簡介有詳細介紹,但是我自己是幾乎沒有調過。
三、Clustering效果比較
這邊我仿照sklearn的實驗,也跑了一個針對目前比較主流的clustering在各種data上的比較,這裡的各個model都是沒有經過tuning的,所以只是比各個model的baseline而已。

這裡要注意HDBSCAN比起其他大部分model更好tune,實際上在這邊所有data上我們都可以把HDBSCAN調到好。
而在運行速度這塊,可以參考下面這張圖,可以看到HDBSCAN比DBSCAN稍快,但是還是比K-Means久不少,所以實際上K-Means在資料量極大的情況還是有使用的必要。

如果想要深入了解HDBSCAN的原理的話,我建議可以看下面這些資料。
HDBSCAN是我在早期做data exploration的時候非常常用的clustering方法,實際的效果也非常穩定可以直接拿clustering的結果來接到ML pipeline上,但是要注意,當我們資料維度較高時,大部分的clustering都會爛掉,HDBSCAN也不例外,所以在資料為度高的時候優先做的事情應該是feature selection而不是clustering。
而在feature selection這塊我之前也有介紹過今年sklearn更新的最新方法
之後也會再寫一兩篇討論在kaggle上還有甚麼常見的方法。
如果喜歡這篇文章可以幫我多拍手幾次XD,或是對於哪個類型文章有興趣都可以在留言區跟我講~ 後續會以中難度的ML/DS/AI知識為主,以及AI/HCI研究相關知識