【Human-Agent-Computer interaction Design】探索打造 LLM agentic system 的各種可能性
2024 下半年,整個 AI 領域經歷了各種狂歡,不只是開源模型 llama3 系列不斷更新,llama3.1 3.2 3.3 每一版都比前面更強一點,OpenAI 更推出了 o1-preview, o1-mini 兩個 reasoning model,開始了 test time scaling 的時代,隨後 deepseek-r1, qwq, qvq, gemini2-flash-thinking, o3各種 reasoning 模型也如雨後春筍而出,中間筆者也跑去玩很多新潮的東西 XD,荒廢了一大段時間。
不過狂歡後,還是要回歸工作 XD。從 2023 年底到 2024,幾乎每一個月都會有某些業界專家、媒體、學術界知名教授提出 Agent 是下一個大機會,但是到 2024 年底我們其實看到真正成功的 Agent 恐怕只在兩個領域:1. Coding Agent,如 Devin、SWE Agent、AIDEr、OpenDevin、MetaGPT 能幫你寫 code、debug、執行軟體工程流程等,節省開發時間與精力,2. Search Agent,如 Perplexity、You.com 可以幫你搜索數十篇網路文章,並整理、總結成一段短文,減輕用戶做調查、研究的時間。其他領域雖然零零散散都有出現一些慣以 Agent 名字的產品,但大多恐怕宣傳的意義都大於實際價值。
筆者也在 2023 下半年就開始透入到 LLM agent 相關的產品設計、技術的學習與研究,並在工作中實際設計過大量的 agent。學到的很多,犯過的錯誤更多,因此筆者打算在 2025 年初,重新整理一些筆者的知識,提供大家參考也希望檢驗我自己思考是否已經全面。(文末還有針對學生、新鮮人的求職活動推薦,想要工作做 LLM Agent 相關都推薦看完本文 XD)
LLM agentic system 的設計其實主要包含了兩個很難的問題:
- 如何設計 Human Agent Interaction:如何設計我們 agent 跟用戶的交互模式,讓 agent 去「以正確的方式」幫助用戶解決問題、執行任務。
- 如何設計 Agent Computer Interaction:如何提供 LLM 有用的工具,讓 LLM 具備能力去代理用戶解決問題,並且如何設計這些工具,提升成功率。

今天這篇我們先針對 Agent Computer Interaction 來進行討論,如何設計我們的 tool set 讓 LLM agent 可以更好的執行任務,也就是大家大概都很熟悉的 LLM tool use (function calling) 這個知識。
0. Tool use 其實不簡單
講到 LLM tool use,很多人可能會想說,這有甚麼難的,不就是 function calling 嗎?
的確如果只是說「如何接通一個 function calling 的範例?讓 LLM 可以使用某一個特定的 tool?」這是超級簡單的事情。整個流程如下,除去執行 function 的部分,大概可以用 30~50 行 python code 解決。

如果對於串通 Function calling 流程還不熟悉,推薦大家可以直接閱讀 OpenAI 的 Function calling Document,照著上面流程跑一遍相信很快可以了解。
但如果只是單純的接通,沒有任何價值,充其量只能做出一些 Demo 而已。我們想要的是 LLM 幫用戶解決具體問題、代理執行任務,而針對 Function calling 這段而言代表我們希望 LLM 能夠「在正確的場景、選擇正確的 Tool、提供正確的參數、並且以正確的方式解讀 Tool 的結果」。
舉個例子,ChatGPT 在 2023 年就一直都具備 browser (search)這個工具,我們看 ChatGPT 的 system prompt 其中也明確提供了 browser (search) 的使用時機。
## browser
You have the tool `browser`. Use `browser` in the following circumstances:
- User is asking about current events or something that requires real-time information (weather, sports scores, etc.)
- User is asking about some term you are totally unfamiliar with (it might be new)
- User explicitly asks you to browse or provide links to references 可以看到其中第二點「如果用戶詢問了一個 GPT 不熟悉的詞,就使用 Browser 來搜索網路資訊」,避免 GPT 自己隨便回答。
但即便到 2024 年底,我們還是可以看到 ChatGPT 並無法真的理解/辨別出這個場景,無法辨識出自己不熟悉的詞,以至於很多問題還是有可能會出現胡言亂語。
舉例而言我們問 ChatGPT 「請問 QvQ 模型特點是甚麼」,QvQ 模型是 2024 12 月 Qwen 團隊新釋出的 Vision reasoning 模型,ChatGPT 的回應如下,可以看出其實他幾乎等於是胡言亂語了。(我們在 IR 的時候也很少會使用 Query versus Query model 這個詞,更不用說用 QvQ 來簡寫,所以 GPT 應該要能區分出 QvQ 是需要搜索的詞。)

而我們只要強迫 ChatGPT 搜索(勾選搜索功能),他就可以很好的回答問題(如下圖)。

因此 Browser 這個 Tool 本身沒有問題,接通 GPT 跟 Browser 的 function calling 流程也很簡單,但只是接通,很多時候並無法帶來價值。
我們來更定量的看這件事,我們參考 Berkeley Function Calling Leaderboard,可以看到即便是最 top tier 的模型,Function calling 的 Overall Acc 也座落在 80% 左右,而 Multi Turn Function calling 則更慘,只有不到 40% Acc。

因此串通 Function Call 不是終點,串通只是起點,後續我們其實還有很大量的工作需要做,讓 LLM 真的懂這些 Tools 怎麼使用,並且在 LLM Agent 需要的時候,能夠正確、輕鬆地使用對應的 Tool。
1. Function Definition
首先我們先從最核心的設計要素 Function Definition 開始,也就是我們進行 function calling 前告訴 LLM 關於我們 function 的相關資訊。

一般而言我們的 function definition 會如下格式(筆者為了方便使用舊版 function calling 格式做示範,但所有內容可以通用到新版 tool call 格式)
{
"name": "get_delivery_date",
"description": "Get the delivery date for a customer's order. Call this whenever you need to know the delivery date, for example when a customer asks 'Where is my package'",
"parameters": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The customer's order ID."
}
},
"required": ["order_id"],
"additionalProperties": false
}
}其中有三個要素必須要有
- name: 這個 tool/function 的名字
- description: 這個 tool/function 的 description(通常會包含這個 tool 的功用、用法、使用時機)
- parameters: 需要傳入的參數,其中我們會重點關注每個參數的 type,以及有哪些 required parameters。
先講結論,這三個都要非常小心設計才可以達成好表現。
我們先來處理 function name,很多人可能覺得我們只要 description 寫得好,講清楚這個 function 要怎麼使用,那 name 其實影響沒有那麼大。
但其實不然,LLM function name 的命名也需要依循 clean code。這邊筆者曾經設計一個實驗,在一個同時提供 10 個 tools 的專案上,嘗試不同的命名方式,而不同 function name 命名方法所搭配 function description 是完全一樣的:
- 5 random letters: 每一個 function 是隨機 5 個英文字母
- toolA, toolB, toolC, … 依序命名
- reverse word spelling: 如果這個 function_name 正常是 get_delivery_date,我們就法它 reverse 變成 etad_yreviled_teg
- snake_case: 使用有意義的命名(從名稱上就可以理解 function 的功能的命名),並且以 snake_cake 格式(用底線分隔單詞,所有字母小寫。)
- camelCase: 使用有意義的命名(從名稱上就可以理解 function 的功能的命名),並且以 camelCase 格式(第一個單詞首字母小寫,後續單詞的首字母大寫)
然後計算 gpt4o 在一樣的 test set 下取用到正確 tools 的機率,結果如下。

可以看到,當我們使用「有意義的命名(從名稱上就可以理解 function 的功能的命名)」,我們效果是顯著高於那些隨意的命名方式。因此 LLM function name 命名也要 Clean code,而具體使用哪一種命名格式則影響較小。(實際上筆者嘗試了大量的排列組合,一樣的結論可以通用到常見不同命名規則、不同 LLM、不同數量的 tools,這邊只是提供有代表性的結果)
這個結論其實也不難理解,因為 LLM 在訓練時 pretraining 階段看到的 json 格式相關資料中,其中大多資料高機率都參考了某一種 clean code 格式,而 SFT 資料經過清理或是特殊設計後,應該也是以標準 clean code 格式命名為主。(注意這裡所有實驗都有搭配一個完整的 function description,所以即便 description 寫得完整,只要 function name 亂寫,效果也會大幅下降)
結論1: function name 需要使用有意義的命名方式,讓 function 的功能、使用場景可以從名稱上就一目了然。
接下來一個顯著的問題就是,如果 function name 這麼重要,那我們是不是乾脆把所有資訊都寫在 function name 上,舉例而言把 description 直接以 snake_case 連在一起,變成 function name。畢竟我們平常寫 code 不這樣做只是不想自找麻煩,但對於 LLM 而言並不麻煩。
但這邊在同一個專案,我們設計了不同「長度」的 function name,我們可以看到 function name 在 3~6 個 tokens 效果是最好的,超過 10 tokens 後效果會顯著下降。

因此我們也不能單純的把所有需要資訊都串到 function name 中XD,還是要找到一個資訊量足、又精簡的 function name。這其實就跟 prompt engineering 一樣,每一個 word choice 都很重要。
其實筆者後來在設計 function name 的時候,都會較嚴格的遵守當下主流的 clean code 原則,像是使用動詞開頭、避免不必要的縮寫、使用常見前綴、避免冗於資訊…等。不過最簡單的方法是把 code 跟我們 implement 的邏輯、使用邏輯全部丟給 gpt4o、claude3.5 Sonnet,讓 LLM 幫我命名,通常都可以比我自己最一開始取的名稱提升 3~5% 準確性。
從 function name 的實驗我們得知遵循 clean code 的命名方式對於 function definition 有幫助(不見得最好,但通常會比我自己拍腦袋寫出來的還要更好),同樣的原理我們也可以應用在 function description 以及 parameter 及對應的 description。我們的 function description 也最好用 plain text 寫清楚這個 function 的用途以及使用時機。
撰寫 function description 其中一個最容易出現的誤區就是,我們寫了「這個 function 的實作內容,希望模型自己去推理使用時機」。
舉例而言,大家都知道不同的 RAG algorithm 分別有不同的優缺點、使用時機,筆者曾經設計一個 RAG agent,同時提供給它以下五個 tools,並且提供對應的 descriptions 說明每個演算法的具體操作(差別只是給 LLM 的內容我寫英文,寫成中文只是方便讀者理解)
- naive_retrieval_with_chunksize_500: 使用 chunk_size = 500 來做 vector search。
- naive_retrieval_with_chunksize_100: 使用 chunk_size = 100 來做 vector search。
- hybrid_retrieval_with_BM25: hybrid 結合 vector search 跟 BM25。
- HyDE_retrieval: 先基於 user query 生成 hypothetical document,再用 hypothetical document 去做 vector search。
- Multi_hop_RAG: 先基於 user query 去做 vector search,再基於 search 到的結果衍伸出第二輪的 query 並基於新的 query 再去做 vector search。
這邊每一個 RAG algorithm 都有自己的適用時機,並且都是經過嚴謹的 tuning,如果選擇的好,可以讓我們當時 Retrieval 的 evaluation score 從 60 分快速上升到 90 分。因此我們就希望 LLM 基於自己對於 RAG 的知識去判斷每一個 user query 進來應該要走到甚麼流程。
但實際上 LLM agent 完全無法基於這些內容去判斷每一個 user query 需要使用哪一個 RAG algorithm,進而導致 LLM agent 其實最常出現兩種行為:
- 隨便選一個 algorithm 然後直接 output,最終效果並沒有提升。
- 把所有 algorithm 依序使用一次,把 model context window 塞爆,Latency、成本大幅增加,效果還有限(大約進展到 75 分)。
同樣的錯誤筆者犯了很多次(間斷性失憶 ...),像是在 image generation 這塊,同時提供 LLM DALL-E, SDXL, Midjourney 三種 tools,希望模型能自行決定使用哪一個,或是在 vision agent 提供 LLM 多種 object detection 演算法、多種 segmentation 演算法,就希望 LLM 能夠自己選出最適合當下 input 的 tool,提升 performance,但效果往往都不如預期。
RAG agent 實驗結果如下,可以看到,每一個 baseline RAG 演算法其實效果差異不大,其中效果最好的 Multi_hop_RAG(3 hops) 隨之而帶來的是顯著較高的 latency(成本也理所當然更高)。
而我們單純在 tool_description 說明不同演算法的差異(niave_tool_description)效果也有限。在 instruction 中請模型把所有 tools 都嘗試過一次(try_it_all_instruciton)雖然效果很好,但 Latency 過高,不適合大部分場景。
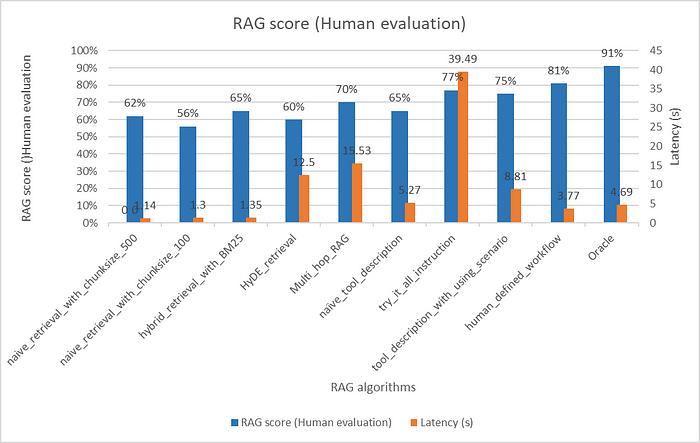
真正帶來效果的 tool_description_with_using_scenario,這是我在每一個 tool 的 description 中詳細說明使用時機。像是當用戶只有打關鍵詞時,請使用 hybrid_retrieval_with_BM25,借助 BM25 做關鍵字 matching 的能力,而 chunk_size 的判斷則是基於猜測這個問題需要被多長的 context chunk 回答,來做猜測。
不過到 2023 年底,因應 RAG 演算法越來越成熟,所以最終筆者套用的做法大多都是直接 define 一個嚴謹的 workflow 如下,可以更好的平衡效果與成本。具體怎麼設計 workflow 我們後續可以再討論。

這邊特別提 RAG agent 這個例子只是帶大家感同身受一下,tool description 如果只寫這個 tool 的功能,很多時候模型無法正確做選擇,更多時候我們要提供使用時機的說明,我們需要在 system prompt 跟 tool description 同時提供 few shot examples 跟一些判斷依據(Ex: 需要做藝術風格圖像生成時可以優先選擇 Midjourney),來增強 model 選擇 tool 的正確性。
而實際上筆者過去在做 coding agent 的時候,很多 coding tools 的 document 其實只寫 tool 的功能,而不寫具體使用時機、場景(可能是預期工程師都知道使用時機)。進而導致直接使用這些 document 的內容作為 LLM tool description 效果往往不夠好,簡單的把使用時機補充上去,就可以得到不錯的效果提升。
結論2: tool description 不只需要撰寫 function/tool 的功用,還要講清楚使用時機(最好在 system prompt)也重複一次。
這個段落講解了 function definition 的撰寫原則,其中專注在 function name 跟 description,要撰寫有意義的內容,讓模型從 name 跟 description 可以清晰了解這個 tool 的具體意義、使用方法、使用時機、...等。
撰寫 function definition 就跟我們做 prompt engineering 一樣,我們需要嚴謹的去實驗、挑選每一個用詞,很多筆者實作的 Agent 專案,單是把 function definition 重新撰寫好,就可以得到 10% 以上的效果提升,並且幾乎沒有任何代價。因此相比於直接 finetune llm 學會使用這個 tool,筆者大多時候會都會先投入 2 週優化 function definition。
2. LLM friendly Function call 設計原則
前一個段落把最基礎的 function definition 的知識講清楚,所有 function calling / tool use 的成功都建立於有一個好的 function definition,因此建議大家在專案執行中都預留 2週~4週的時間認真時間 function definition 的各種細節。
接下來我們開始探索一些增加我們 function call/tool use 的設計原則、技巧,為了讓 LLM 更好使用這些 functions/tools,我們需要參考 LLM 本身的能力,去重新思考我們的設計方法。
❗ 原則1:盡量不要讓 LLM 得到 >10 個 tools。
原則 1 很好理解,tools 越多我們光是 tools 相關的 prompts、function definitions 就越長,因此模型需要更強的 long context understanding 能力才能正確理解多個 tools,同時我們每一次 function calling 的選擇也更多,因此本身也變成一個更難的 classification 問題。
而 10 這個數字是一個筆者實驗多次的經驗結果,通常超過 10 個 tools 後效果就會明顯下滑。因此我們通常會建議選擇一個正確的 tool 封裝層次,讓 LLM agent 只需要零散 3~5 tools 就可以達成它主要的任務。
但如果我們真的需要這麼多 tools 呢?如果真的我們的場景需要數十個甚至上百個 tools,也沒有更好的封裝方法,那不外乎就是用兩個方法解決:
- tool retrieval: 每一次基於 user query 抽取最相關的 tools [3],在把這個 tools 丟給 LLM 參考。
- Multi agent: 把大量的 tools 分派給幾個不同職責的 agent,讓每一個 agent 還是只需要看到不超過 10 個 tools,再藉由 agents 之間的協作達成任務。
Multi agent 這條路其實筆者只有在一個專案有得到比較好的成效,因為大多數時候 agent 與 agent 之間的溝通失敗率更高。
因此筆者更專注在做 tool retrieval,而在這邊就可以沿用 RAG 常見的各種技巧,Query rewriting、基於 document 生成假的 query 來做 search [4]、基於 query 生成假的 document 來做 search [5]。
甚至可以先從 User Query 來 search 出比較好的 workflow,再參考 workflow 上使用的 tool 以及如何使用。[6]
其中特別推薦 Re-Invoke[4] 這個方法,基於每一個 tool document 生成對應這個 tool 可能會面對的 hypothetical query,每一次 user query 進來再跟這些 hypothetical query 做比對,筆者在好幾個專案上只要每一個 document 的 hypothetical query 生成數量變多後,就可以顯著提升 tool call 成功率。


❗ 原則2:tool calls 設計要讓模型盡量可以以 "盡量少的 tool call 次數" 就完成任務。
回顧 Berkeley function calling leaderboard,可以看到 Multi Turn/Multi step 的 tool call 成功率都很糟,因此我們要盡量避免 tool 設計成模型要來回使用多次才能達成一個任務。也就是說我們往往需要捨棄 tool 的使用彈性,而以 end to end 的角度來設計 tool。
在 CodeAct [7] 論文中就有討論這點,基於 CodeAct 的執行方法(用 python code 來執行 function,而不是以 API call 的形式),可以大幅減少需要做的 action 數量,進而大幅提升成功率。

不過因為我們本篇文章專注在 tool 設計,所以這邊筆者想強調的,tool 設計上我們也應該要遵守「解決任務所需 tool call 越少越好的原則」。
舉例而言,如果我們要提供 RAG 相關的 tools,傳統的 OOP 經驗會告訴我們應該把 module 拆解開,讓每一個 module 只需滿足單一職責,進而讓開發者有足夠的彈性去做組裝。(如下圖)

但如果我們真的把 RAG 的每個步驟都封裝成獨立的 tool,那我們就會面臨大量的 tools(違反原則1),同時 LLM agent 單只是想要做 RAG 這個任務,可能就需要先後使用 5 個 tools 才能執行一次 RAG 任務,也大幅增加失敗率。
因此我們應該封裝成下圖下面的形式,把整個 RAG 流程封裝成單一一個 tool,其中固定的流程就直接執行,而需要選擇的流程則提供 argument 讓 LLM 做控制。

這樣既減低了 tools 的數量,也減輕了每一次 RAG 所需要的 tool call 次數。
❗ 原則3:注意 LLM 容易填寫失敗的 arguments,並針對這些 arguments 做 error handling
有一些 arguments 因為 LLM 本身能力限制或是過去資料比較缺乏,LLM 容易填寫失敗,針對這些 argument 我們都需要做一些應對。
主要有4種情況
- 漏填
- 超出 argument 數值合法範圍
- 格式錯誤
- 內容轉譯錯誤
其中前3個都很好理解,解法也很直接,就是我們在做設計 function 時,我們提供必要的 default value,讓我們模型即便漏填某些 argument 也可以正常運行,以及對 LLM 填入的格式、數值範圍進行規範,如果出錯我們要在 error message 中提供詳細的說明,讓 LLM 下一次可以修正。
4 內容轉譯錯誤是一個比較嚴重且不容易解決的問題,舉例:時間的轉譯,大多數的 API 如果有時間先關的 argument,都是希望用戶填入特定的 datetime 格式,ex: 2024–12–29 15:45:30,但用戶在跟 LLM 對話時,大多時候可能是說「幫我確認上週五有哪些貨品到貨」、「幫我預約下下禮拜六的車票」...等。
這種口語化的「相對時間觀念」轉譯成特定格式的絕對時間,對於 LLM 其實是很困難的任務。舉例而言,我們問 gpt-4o 詢問「今天是2024/12/29 星期日,請問上週五是幾月幾號」,模型其實有 50% 左右機率會回答 12/27。(不確定這是不是文化、語言結構差異,如果在英文文化中這樣是合理的嗎?尋求英文專業的人幫筆者解惑 XDD)

同樣的問題問 ChatGPT (一樣選擇 4o)卻可以 90% 機率成功。

為甚麼呢?因為 ChatGPT 知道自己時間轉譯的能力較差,所以直接讓模型調用 python tools,來做精準的時間運算。

因此如果我們的使用場景下,我們的 tool 也需要讓 LLM 輸入精準時間,ex: 預定車票、查訂貨狀態...等,我們也可以一樣提供 LLM python tool,藉由 python tool 來做時間的轉譯。(實際上更好的方法是把時間轉譯這個步驟封裝在 tool 流程中,只要這個 tool 需要指定時間,就先過一個 LLM + python tool 的流程來取得精準的時間)
而其他像是牽扯到的數學運算、時區換算、貨幣換算、最新資訊...等這些我們已知 LLM 做不好的事情,我們都需要幫助 LLM 來設計補償機制,避免遇到這些場景 LLM 就都常態失敗。
❗ 原則4:在 tool definition / few shot examples 累積 tools 使用的經驗
前面提到的大多都是 LLM engineer 介入,去對 LLM 的行為做 error analysis,並針對這些 error / LLM 缺陷設計出對應的解決方法。但系統設計上,如何讓我們 LLM agentic system 可以自己演化,從過去自己犯過的錯誤中學習,是另一個一樣重要的問題。
我們已知,不同用戶使用同一個 LLM agentic system,其中只有 system prompt 跟 tool definition 是共享的,因此我們可以把過去在其他用戶使用紀錄上已經犯過的錯誤,回頭紀錄到 tool definition(尤其是 tool description),或是回頭更新 few shot examples,讓 LLM agentic system 可以隨著用量越大,成功率越高。
其中 DRAFT [8] 是一個筆者最近實驗起來效果很好的方法,基於每一次 LLM 使用 tool 的經驗,去 improve tool description,移除多餘或錯誤的資訊,補充必要資訊及範例。

只需要經過幾個輪次,LLM 就能修改 tool description 變成 LLM friendly 的內容,避免重複犯錯。

結語
本篇文章從 function calling 的基礎流程開始講解,並說明被很多人忽視的 function definition 比想像中還要重要,function name, description 的內容就如同 prompt 一樣,需要我們嚴謹的做實驗去挑選每一個用詞遣字。這些就是 LLM engineer 時代的 hyperparameter tuning,學界論文不會討論,但在業界工作時 30% 時間都在做 hyperparameter tuning。
而後又衍伸出了一些基於 LLM 能力上限制帶來的 function call 設計原則,包含不要讓 LLM 看到太多 tools,避免對 LLM long context 能力帶來壓力,或是選擇變太多,導致 classification 本身問題就變難。同時也要讓單一任務執行所需的 tool call 數量盡量減低,以及注意到 LLM 本身在某些類型的 argument 就容易填寫錯誤,進而我們需要做一些補償機制,以及如何避免 LLM agentic system 重複犯錯。
後續其實還有 function response 設計、function interface 設計、...等很多議題需要討論,我們放在未來的文章再接續。
這裡很推薦大家去閱讀 Anthropic 的 Building effective agents,其中提到我們需要設身處地把自己當成 agent 來思考,我們的 function 設計真的有足夠直覺嗎?
Put yourself in the model’s shoes. Is it obvious how to use this tool, based on the description and parameters, or would you need to think carefully about it? If so, then it’s probably also true for the model. A good tool definition often includes example usage, edge cases, input format requirements, and clear boundaries from other tools.
Function definition 結論
結論1: function name 需要使用有意義的命名方式,讓 function 的功能、使用場景可以從名稱上就一目了然。
結論2: tool description 不只需要撰寫 function/tool 的功用,還要講清楚使用時機(最好在 system prompt)也重複一次。
LLM friendly Function call 設計原則
❗ 原則1:盡量不要讓 LLM 得到 >10 個 tools。
❗ 原則2:tool calls 設計要讓模型盡量可以以 "盡量少的 tool call 次數" 就完成任務。
❗ 原則3:注意 LLM 容易填寫失敗的 arguments,並針對這些 arguments 做 error handling
❗ 原則4:在 tool definition / few shot examples 累積 tools 使用的經驗還沒結束,文末還有針對學生、新鮮人的求職活動推薦,想要工作做 LLM Agent 相關都推薦看看 XD
Reference
- OpenAI function calling document https://platform.openai.com/docs/guides/function-calling
- Anthropic Building effective agents https://www.anthropic.com/research/building-effective-agents
- Patil, Shishir G., et al. “Gorilla: Large language model connected with massive apis.” arXiv preprint arXiv:2305.15334 (2023).
- Chen, Yanfei, et al. “Re-Invoke: Tool invocation rewriting for zero-shot tool retrieval.” arXiv preprint arXiv:2408.01875 (2024).
- Mao, Kelong, et al. “Large language models know your contextual search intent: A prompting framework for conversational search.” arXiv preprint arXiv:2303.06573 (2023).
- Wang, Zora Zhiruo, et al. “Agent workflow memory.” arXiv preprint arXiv:2409.07429 (2024).
- Wang, Xingyao, et al. “Executable code actions elicit better llm agents.” arXiv preprint arXiv:2402.01030 (2024).
- TOOLS, TO MASTER. “From Exploration to Mastery: Enabling LLMs to Master Tools via Self-Driven Interactions.”
活動推薦
如果有學生對打造 LLM agentic system 相關有興趣,或是正在尋找相關工作,很推薦可以參加台積電 IT 部門的黑客松(也是筆者前東家,目前台灣 Agent 做的前幾深入的部門),今年的主題是滿滿的 Agent XD,推薦同學們參加。
- 活動/報名網址:https://www.tsmc.com/static/english/careers/Careerhack/index.html
- 獎品:總價值新台幣 60 萬元
- 報名截止時間:1/5(日),只剩一週!
- 活動時間:2/14、2/15
- 報名資格:大二以上學生以及應屆畢業生
偷偷說,如果是相關領域的應屆畢業生,筆者建議都先報名,因為台積 IT 目前具備台灣做 AI 最好的幾個條件(很多很多的 GPU、實際應用場域、專家資料、技術優先的工作環境 … 等),即便未來想要去外商、新創,都很值得先到台積練功,可以體驗到很多在學界不容易體驗到的事情。(薪水也是真多)
同時參與台積電 IT 黑客松可以讓你有三個求職的優勢
- 參賽途中可以直接接觸到部門主管,可以帶著履歷去參賽,也可以先認識主管、同事,大幅增加未來面試機會。(不然很多人履歷其實也不是不好,就是沒被主管撈到而已 ...)
- 初賽的程式測驗,可以直接當成入職的程式測驗,等於是「多一次機會」。(平常一年只有 2 次,沒有把握好就是明年再來)
- 了解實際業界在意的問題是甚麼,在 LLM 這段,其實學界跟業界思考的問題、視角差距很大,所以求學期間如何增加業界的視野、了解業界如何使用 LLM,這點到其他公司也都有幫助。
如果擔心自己對 LLM Agent 不熟無法參加台積電 IT 黑客松,筆者這裡提供一個月的學習素材,只需要一個月,我相信相關領域的同學都可以很快上手,到 2/14 15 綽綽有餘。
1個月 LLM Agent 學習計畫
- [2天] 熟悉使用 LLM function call,參考 OpenAI function calling document 以及 deeplearning.ai Function-Calling and Data Extraction with LLMs 課程。
- [3天] 熟悉使用 Langchain 建構出最基本的 LLM agent,參考 deeplearning.ai Functions, Tools and Agents with LangChain 課程、LangChain for LLM Application Development 課程、Langchain Agent Document、Langchain Agent Tutorial
- [5天] 利用 Langchain 建立第一個 Agent 應用,以 csv agent 為例。參考 Langchain csv agent document、並且自己搜索生活邊的 excel 範本進去測試,並嘗試調整 prompt、tool 來讓自己生活中的 excel 都可以被正確使用。
- [2天] 補充 Agent 相關知識,參考 Anthropic Building effective agents 以及 Lilian Weng LLM Powered Autonomous Agents,重點放在理解 Agent 主體架構。
- [2天] 案例分析:分析 Andrew Ng translation agent 的設計巧思。理解如何使用多步的 workflow 來增強 translation 能力。
- [5天] 利用 Langchain/llama index 建立第二個 Agent 應用,以 RAG agent 為例。參考 Langchain RAG agent tutorial、Deeplearning.ai Building Agentic RAG with LlamaIndex 課程
- [11天] 知識補充,參考 Large Language Model Agents 課程,補充 2024 最新的 agent 知識,並以 langchain, llamaindex 實踐。